※ 개인적으로 받았던 Kubernetes 교육을 정리한 내용입니다.
1편 > Kubernetes 아주 조금만 알아보자 - Kubernetes란? : https://koocci-dev.tistory.com/3
2편 > Kubernetes 아주 조금만 알아보자 - Kubernetes의 흐름 : https://koocci-dev.tistory.com/5
3편 > Kubernetes 아주 조금만 알아보자 - 마스터, 노드 : https://koocci-dev.tistory.com/6
4편 > Kubernetes 아주 조금만 알아보자 - Model, Declared State, Pod : 현재 Post
5편 > Kubernetes 아주 조금만 알아보자 - ReplicaSets,Deployments : https://koocci-dev.tistory.com/11
6편 > Kubernetes 아주 조금만 알아보자 - Service : https://koocci-dev.tistory.com/12
Model과 Declared State 선언은 어떻게 하나?
우리는 이제 만들고 싶은 모델과 Declared State를 선언하고 싶을 것이다.
이를 순차적으로 어떻게 선언하는지 알아보자.
- 선언은 MS(Manifest File)로 한다. - YAML/JSON
- 어떤 image를 쓸 것인가?(Registry에 있어야 한다), 얼마나 많은 Replica를 가질 것인가?(Scale), 어떤 network를 실행시킬 것인가?(어떤 Pod에 있을 것인가) 어떻게 Update를 할 것인가? 등
- Kubernetes API에 MS를 POST 한다. (흔히, kubectl(CLI)를 사용한다.)
- Kubernetes는 Application의 Desired State로 위 내용을 cluster store에 저장한다.
- Kubernetes는 Application을 cluster에 배포한다. (Controller)
- image를 Pulling, Container를 시작, Network를 Building 등
- Kubernetes는 Watch loops를 통해, Desired State와 달라지지 않도록 한다.
- Cluster의 Actual State가 Declared State와 다르면 Kubernetes는 Manifest File을 사용하여 이를 수정한다.
위 내용에서 1번 내용을 보면, 최종 모습만 Declare한다는 것을 볼 수 있다.
4번의 내용에서 배포가 될 때는, 대부분 Pod가 Scheduling되는 일이 진행된다.
마지막으로 5번을 보면, Desired State와 달라지지 않게 한다고 하였다.
이는 장애가 발생되거나 혹은 변경이 일어났을 때, 즉, 장애가 났을 때는 Actual State가 바뀌는 것이고, 변경은 Desired State가 바뀌는 것으로, Gap이 발생하는 것이고, Actual 을 바꾸어가며 맞추어 간다.
위 내용을 이미지로 순서대로 보도록 하자.
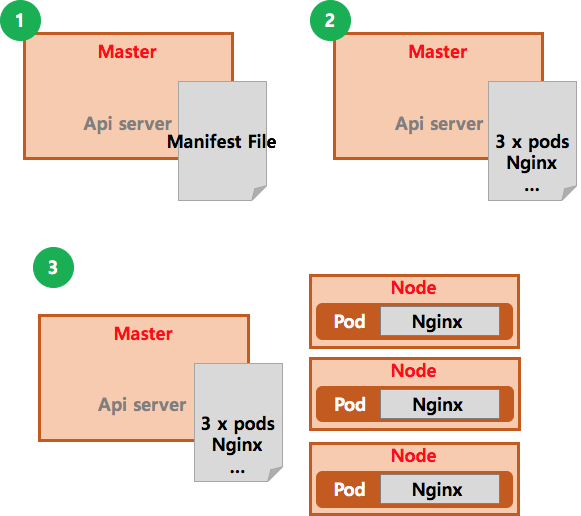
- YAML 이나 JSON으로 표현된 Desired State를 API Server에 POST한다.
- 해당내용에는 Nginx Pod를 3개 띄우겠다고 선언되어 있다.
- 선언된 내용대로 Node내에 Pod를 만들어 띄운다.
이후에 Pod를 하나 지워보도록 하자.
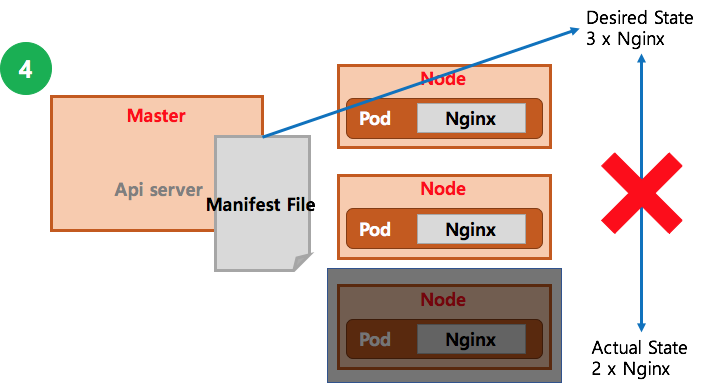
위와 같은 상황에서는 현 상태와 Desired State는 Gap이 발생하게 되고, 다음과 같이 진행된다.

이렇게 스케줄러가 자기의 정책상으로 알아서 Pod를 하나더 띄우면서, Desired State에 맞춘다.
Pods 란?
앞서, 우리는 계속해서 Pod라는 것을 언급해왔다.
한번 설명한 적이 있지만, Pod는 Kubernetes의 스케줄링 기본 단위이다.
단, Container와는 다르며, Container를 포함할 수 있는 Container정도로 설명될 수 있다.
또한, 다른 말로 Atomic unit of deployment라고도 한다.
Container들은 항상 Pods안에서 돌아가게 되며, Pods는 여러 Container들을 가질 수 있다.
그 예시들은 다음과 같다.
- Service Meshes
- Web container + helper container
- Web container + tightly coupled log scraper
다만, 보통 Container를 1개만 두며, (Atomic Unit이므로) 2개라고 하더라도 1개는 보조의 역할을 한다.
위 예시 내용들은 추후 조금씩 알아가도록 하자.
참고로, 2개 이상의 Container를 같이 쓴다면, 이는 공유할 수 있는 설정이 있다. (co-location)
Container를 공부하다보면, C-Group이나 Namespace와 같은 리눅스 내용들을 접할 수 있는데, 이들이 그 설정을 도와준다. [참고 : https://tech.ssut.me/what-even-is-a-container/]
Namespace는 리눅스 내에서 독립적인 환경을 구성할 수 있는 공간을 마련해 주는 것으로, 다음과 같다.
- mnt (파일시스템 마운트): 호스트 파일시스템에 구애받지 않고 독립적으로 파일시스템을 마운트하거나 언마운트 가능
- pid (프로세스): 독립적인 프로세스 공간을 할당
- net (네트워크): namespace간에 network 충돌 방지 (중복 포트 바인딩 등)
- ipc (SystemV IPC): 프로세스간의 독립적인 통신통로 할당
- uts (hostname): 독립적인 hostname 할당
- user (UID): 독립적인 사용자 할당
또한, C-Group은 Resource(자원)들에 대한 제어를 제공하는 리눅스 커널의 기능이다.
제어가능한 내용은 다음과 같다.
- 메모리
- CPU
- I/O
- 네트워크
- device 노드(/dev/)
이전 첫번째 포스트에서 이렇게 언급한 적이 있다.
Docker는 Kubernetes의 container runtime (kuberlet)으로 일하고, 이 둘을 연결하는 Interface가 CRI(Container Runtime Interface)라고 한다.
조금 더 깊게 들어가면 OCI(Open Container Initiative:컨테이너 포맷과 실행환경의 표준) 스팩을 만족하는 Docker Engine을 Kubernetes와 통신하게 만든 규격이 CRI이다.
위에서 OCI 부분이 C-Group, Namespace를 표준으로 정의해둔 것이며,
Docker 엔진 내에서 runC가 위 OCI를 구현해놓은 Docker 자체 구현체이다.
그럼 아래와 같은 Docker의 내용이 좀더 자연스럽게 이해될 수 있을 것이다.

containerd가 OCI 구현체(흔히, runC)를 이용해 container를 관리하는 daemon이며, Docker Engine이 이미지, 네트워크, 디스크 등의 관리 역할을 한다.
위와 같이 분리가 되어 있어, Container를 재시작하지 않고, Docker Engine만 버전을 올리는 것이 가능하다.
다시 Pod 이야기로 돌아와서, 앞서 Pod 내에서는 Container가 보통 1개라고 했다.
Scale 작업도 마찬가지로 Pod를 늘리지, Pod안의 Container를 늘리지 않는다.

각각의 Pod를 설정해두면, 각각 IP를 달리 잡을 수 있다. (Port는 동일) 그러나 오른쪽처럼 잡는 경우, 하나의 TCP/IP 스택에 들어가며 Port 충돌이 발생할 수 있다.
Pods Lifecycle

위 이미지를 보면 Phase가 4가지 있는 것이 보인다.
제일 처음 화살표의 시작이 Controller가 생성되었을 때이다.
Pod들은 Mortal, 즉, 언제든 죽을 수 있다. 태어나서, 살다가, 죽는 과정이 있다는 것이다.
다만, 위 내용들이 Cattle하게 진행되어야 한다.
먼저 Pending과정이 생성될 때의 기다리는 순간이다.
Pod들은 Atomic하기 때문에, 생성되었거나, 안되었거나 두가지 경우만 가진다.
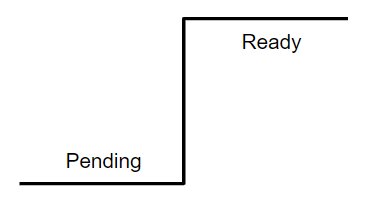
그렇게 Ready 상황이 되고, Running 상태로 진행되어, 서비스가 실행된다.
그런데 Pod가 죽었다고 하자, (보통 1번 Container의 1번 Process가 죽으면 Pod가 죽은 것으로 설정한다.)
그럼, succeeded/failed 둘 중 한가지 상태로 남게 된다.
succeeded는 정상 종료가 남은 상태이고, failed는 비정상적으로 종료된 것이다.
그러나, 상태로 봤을 때는 어떻든 둘다 죽은 것으로 간주된다.
이때, 죽은 Pod를 다시 되살리는 개념이 아니라(cattle) 그 갯수를 맞추어 줄 뿐이다.
따라서, 새 Pod를 띄우고 scheduling이 된다.
즉, Pod는 stateless 해야하고, 의존적인 Data는 없어야 한다.
Cattle하게 진행되며 언제든 죽을 수 있는 Pod인데, Host에 정보를 남기는 건 좋지 못하다.
그러므로, Stateful 한 내용은 Persistant하게 제 3위치에 있는 것이 좋다.
이후에 이렇게 정책상으로 Replica들을 띄운다거나 하는 내용은 다음 포스트에 이어서 하자.
'Architecture > k8s' 카테고리의 다른 글
| Kubernetes 아주 조금만 알아보자 - Service (0) | 2019.06.06 |
|---|---|
| Kubernetes 아주 조금만 알아보자 - ReplicaSets,Deployments (0) | 2019.06.05 |
| Kubernetes 아주 조금만 알아보자 - 마스터, 노드 (0) | 2019.05.21 |
| Kubernetes 아주 조금만 알아보자 - Kubernetes의 흐름 (1) | 2019.05.20 |
| Kubernetes 아주 조금만 알아보자 - Kubernetes란? (0) | 2019.05.17 |